


构建 AI 击键数据集
考虑一下这个问题:
描述一下您的早晨通勤情况 - 您如何去上班以及需要多长时间?
并有两条回应:
A: 我大约 8 点开车离开家。大约需要 20 分钟。
B: 我早上的通勤总距离约为 5.2 英里(8.4 公里)。我从公寓步行半英里(0.8 公里)到阿什蒙特站,然后乘坐红线地铁约 4.3 英里(6.9 公里),之后再从市中心站步行 0.4 英里(0.6 公里)到我的办公楼。整个行程通常需要 35 分钟。
AI 的回答显而易见——它包含距离转换、不必要的细节以及完美的段落结构。虽然人类也能写出这样的文章,但他们很少在匆忙的在线调查中这样做。
AI 击键模式
通过关注人类和人工智能答案明显不同的问题,我们构建了一个包含标注答案及其对应打字模式的大型数据集。虽然答案内容通常相似,但打字模式却显示出一致的差异。
人类打字的自然差异性是显而易见的。按键之间的时间间隔遵循一个特征分布,其中停顿和突发是随机的,停顿最常出现在单词和短语的末尾。例如:
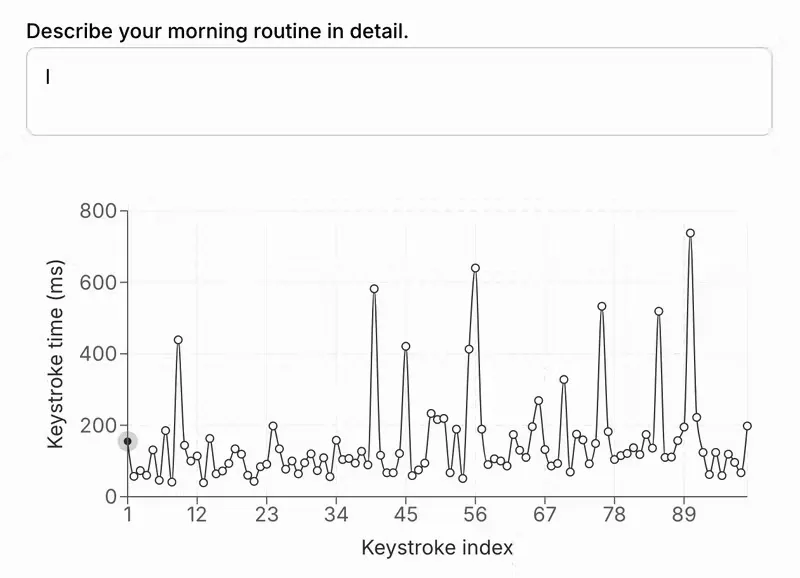
人类也会犯错,并使用退格键和其他编辑技巧来修复。相比之下,AI 的响应通常表现出不自然的按键间隔一致性,差异很小,并且几乎不包含更正或退格键:
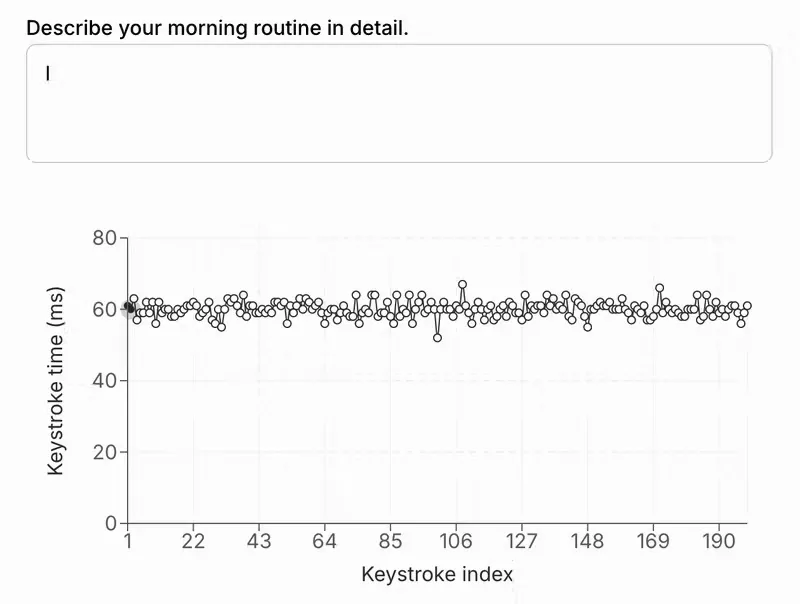
这种程度的击键一致性几乎是人类不可能复制的。
其他人工智能响应看起来像是人机混合,其中人工智能以编程方式输入文本,然后人类编辑响应:
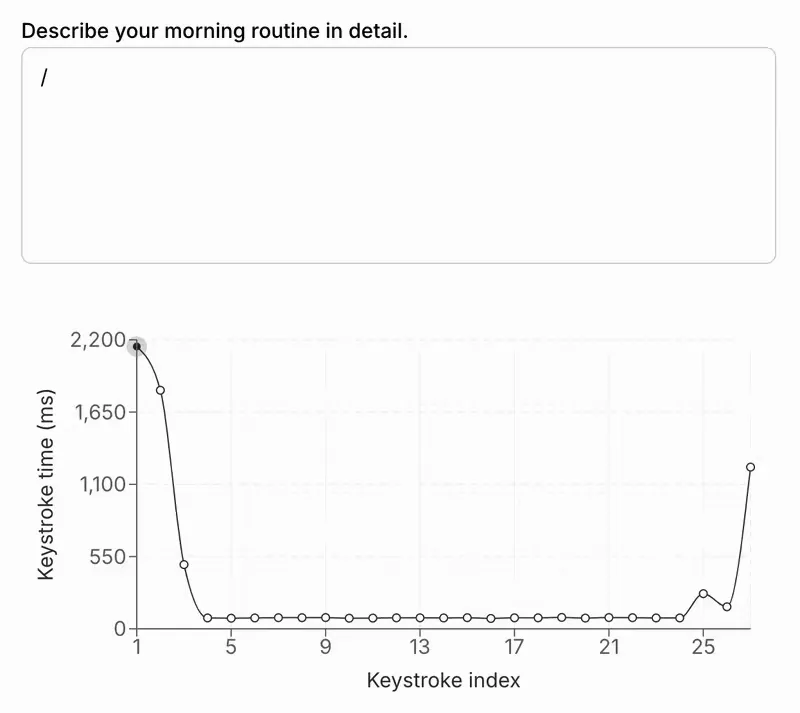
现实世界的影响
为了说明不良行为者如何破坏调查数据,我们对一款故意制造的劣质产品——太阳能冷藏帽——进行了一项测试研究。通过将回答分为“人类”或“人工智能”,我们发现人工智能的回答在下游分析中造成了两类问题。
首先,人工智能的回答显示出了始终更高的支付意愿(人工智能 135 美元,人类 40 美元),这与人工智能相对于人类回答的乐观态度的普遍模式相一致。
其次,AI 的回应增加了噪音。人类的回应形成了合乎逻辑的客户群体(例如积极主动、漠不关心等等),而标记的数据则形成了毫无意义的群体——例如,某个群体认为这顶帽子非常有用,但却不愿意付费。
结论
通过文本分析识别人工智能内容极其困难,而且通常不可靠。我们认为,分析打字模式可能会更加可靠。复杂的按键数据提供了清晰的信号,这些信号比单纯的内容更难伪造(通常也更容易理解)。当然,这是一场猫捉老鼠的游戏。随着检测方法的不断发展,规避技术也在不断改进,我们也在不断更新我们的模型。



